※ 商品のリンクをクリックして何かを購入すると私に少額の報酬が入ることがあります【広告表示】 Data Scientist になろう で紹介した通り、 Python の科学技術系ライブラリを使うのが非常に簡単になっています。 なんせ、GUIインストーラでほとんど必要なライブラリが入ってしまうのですから。
Python を使う強みは csv や tsv といったデータの準備段階からすべて Python でできる(シチュエーションが多い)ところにあるようなので、今回は MySQL からデータを取り出してそのままプロットしてみました。
IPython Notebookは、ブラウザに打ち込んだコードを次々に評価でき、リアルタイムにプロットした画像が表示されるので非常に面白いです(通常のインタラクティブシェルでやるとプロットしたウィンドウが別に開き、ウィンドウを閉じるまでインタラクティブシェルがロックされたりして哀しいんですが)。
余談ですが、世の中の誰かが R と比較していて、それによると Python の方が 2倍高速に動作したりする、らしいです。ソースは忘れました。
さて、 Python3.3 から MySQL を使うために、 pymysql3 をインストールしておいてください。パーフェクトPythonを買っていればおそらくライブラリのインストールには強くなっていることでしょうが、念のため。pymysqlはpure pythonなのでmysqlのヘッダファイルとか不要です。ヘビーに使わない場合に重宝しています。
Data Scientist になろう に出てきた bin ディレクトリに pip がありますので、以下のように実行します。anacondaをインストールした先によっては管理者権限が必要かもしれません(コンソールを管理者権限で開いたり、 sudo したりは OS によって異なる)
$ ./pip install pymysql3
サンプルデータのSQLは こんな感じ(Gist) です。手抜きです。
(実行環境)
import sys;print(sys.version)
#3.3.2 |Anaconda 1.6.1 (x86_64)| (default, May 17 2013, 11:37:53)
#[GCC 4.0.1 (Apple Inc. build 5493)]
必要なモジュールやらを import します。結局 numpy は生では使いませんでしたが…
import pandas as pd
from pandas.io import sql
import numpy as np
import pylab as plt
import pymysql
データベースからデータを抽出する
sql.frame_queryは、sqlとconnectionとsqlへバインドする変数の配列を受け取って、DataFrameを返す。今回は条件が無いので引数は2つ。
con = pymysql.connect(host='192.168.215.128', user='panda', passwd='weakpassword', db='pandasample')
df = sql.frame_query('''select sbj.title as title, stdnt.gender as gender, scr.point as point
from subject sbj, student stdnt, scores scr
where sbj.id = scr.subject_id and scr.student_id = stdnt.id;''', con)
genderごとのDataFrameを作る。
men = df[df['gender'] == 1]
women = df[df['gender'] == 2]
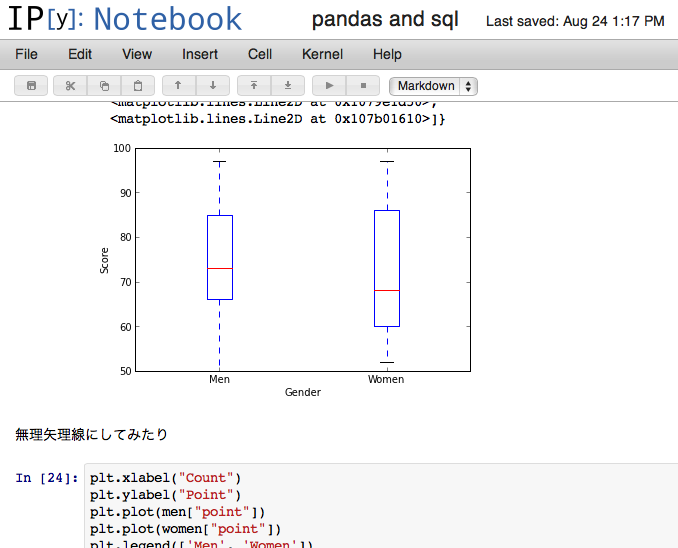
男女の得点を、それぞれの箱ひげ図を出力してみます。
plt.xlabel("Gender")
plt.ylabel("Score")
ax = plt.gca()
plt.setp(ax, xticklabels=["Men", "Women"])
plt.boxplot([men['point'], women['point']])
サンプルデータを40+ランダムで最大100となるように生成したので、あまり面白くない分布になってしまっています。
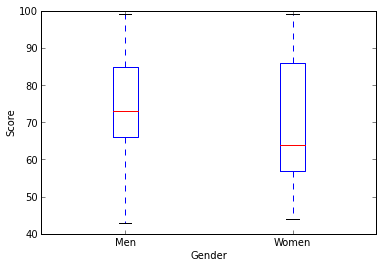
男女の得点をさらに教科で抽出してみます。
menだけを評価(実行)してみたり、men['title'] == 'science']だけを評価してみればDataFrameのデータ抽出の雰囲気がわかるので、やっていると良いでしょう。
men_sience = men[men["title"] == 'science']
women_sience = women[women["title"] == 'science']
plt.xlabel("Gender")
plt.ylabel("Score")
ax = plt.gca()
plt.setp(ax, xticklabels=["Men", "Women"])
plt.boxplot([men_sience['point'], women_sience['point']])
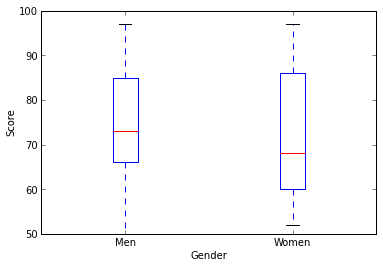
無理矢理線にしてみたり
plt.xlabel("Count")
plt.ylabel("Point")
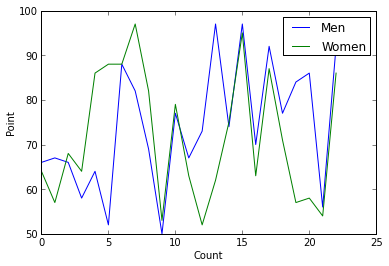
plt.plot(men["point"])
plt.plot(women["point"])
plt.legend(['Men', 'Women'])
無理矢理ヒストグラムを重ねてみたり
plt.xlabel("Point")
plt.ylabel("Count")
plt.hist(men["point"], color="blue")
plt.hist(women["point"], color="red")
plt.legend(['Men', 'Women'])
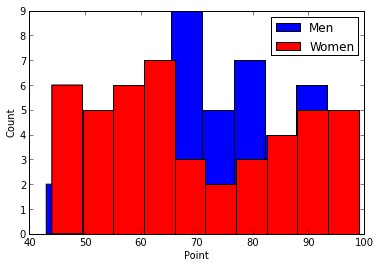
非常に簡単にできます。
IPython Notebookは、保存したファイルを取り込むこともできます。
このipynb を保存して、notebookの一覧ページ(ipython3_mac.commandを実行したらブラウザで開くページ)の一覧にドラッグアンドドロップするか、 click hereをクリックして読み込めます。
あー、便利。